Auckland University of Technology:
Data Mining - 27 October 2023
Code:
Jupyter Notebook - on GitHub
Data Information:
Fake and Real News - Kaggel Fake and real news dataset
Case Study: Text Classification- Evaluating Three Classification Algorithms Across Two Distinct Datasets - A Comparative Analysis
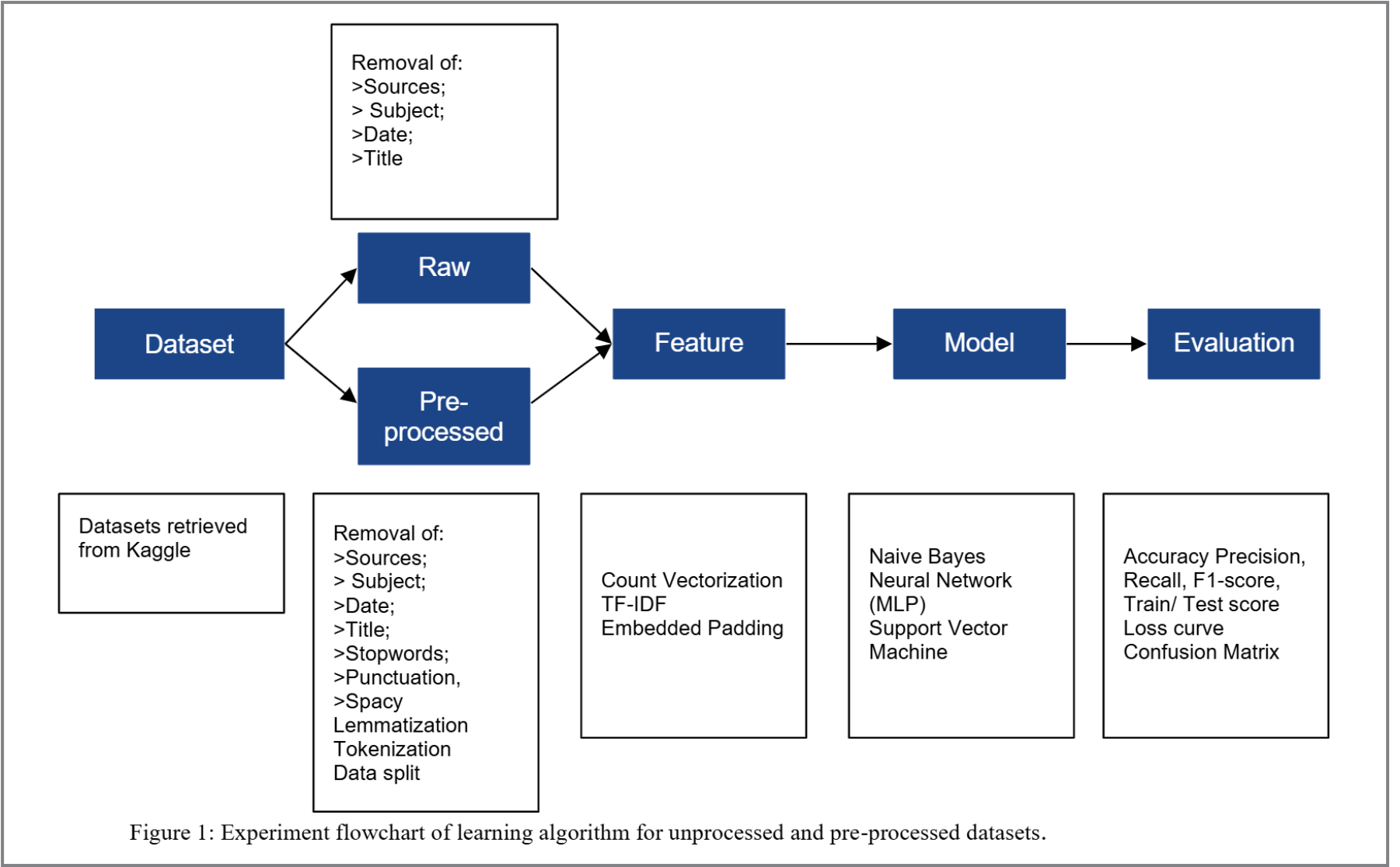
This project was conducted as part of the Data Mining course within the first year of the Graduate Diploma in Computer and Information Science. Python programming language was utilised for the implementation.
Objective:
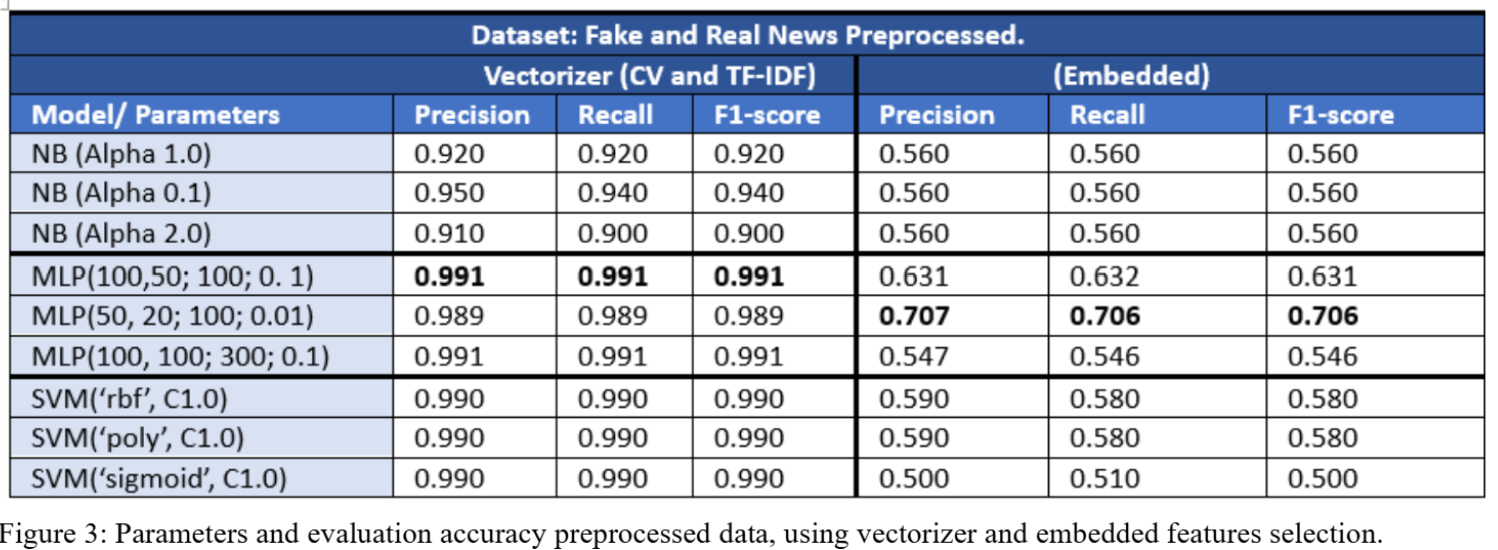
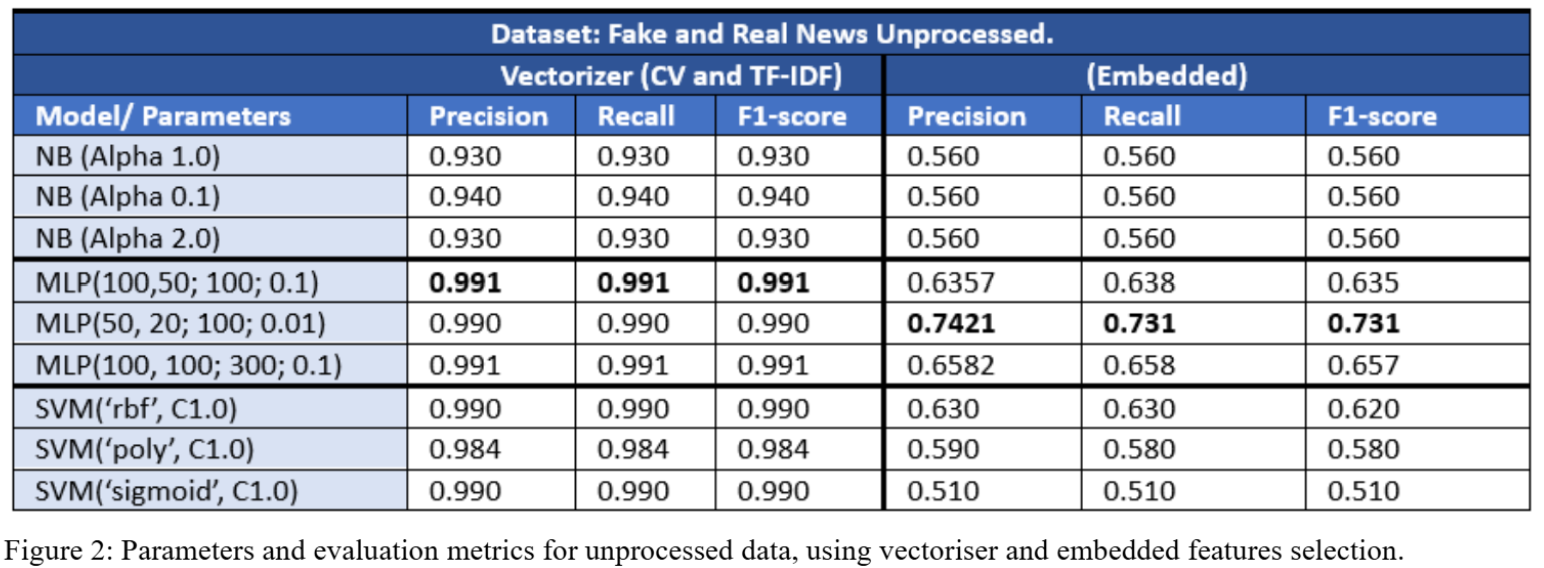
The primary objective was to enhance the performance of three algorithms, Multinomial Naive Bayes, MLP and SVM and improve data quality by employing a wide range of preprocessing techniques. In the first experiment, I achieved the best scores with raw datasets by optimising models with various parameters and using feature engineering techniques. In the second experiment, I continued to employ the optimised algorithms, testing them with processed datasets using different preprocessing techniques. For the ‘Fake and Real News’ dataset, the preprocessing techniques used in the experiment included stop word removal, SpaCy lemmatisation, as well as CountVectorizer and TF-IDF for feature engineering that were compared with Embedding, and tuning the algorithms to find best parameters. Through iterative experiments with these techniques, I identified a model, preprocessing method, and feature engineering technique that produced the best outcome, achieving a 0.99 for the three evaluations metrics (Precision, Recall and F1-score). The report also compares the similarities and differences between the three algorithms, preprocessing techniques, and feature engineering techniques in detail which provides valuable insights for future projects in the realm of text classification and sentiment analysis.
Key Features:
The project focuses on text classification, a critical NLP domain, detailing the categorisation of digital texts into topics like scientific articles, news, and reviews. It highlights the challenges posed by diverse data formats, vocabularies, and overlapping categories, and showcases the application of multiple machine learning algorithms to achieve optimal performance.
- MNB: Based on word frequency and probabilistic principles.
- MLP: Deep learning model for complex, non-linear data.
- SVM: Separates data using optimal hyperplanes.
- Vectorisation: CountVectorizer and TF-IDF.
- Embedding and Padding: For semantic representation.
- MLP with Vectorisation achieved the highest performance (Precision, Recall, F1-score: 99.1%).
- Embedded features generally resulted in lower accuracy.
- Unprocessed data surprisingly performed on par with preprocessed data.
Tools Used:
- Libraries: spaCy, TensorFlow, Scikit-learn, NLTK.
- Feature selection: TF-IDF, CountVectorizer, GloVe embeddings.
- Data Visualisation: Matplotlib, Seaborn.
Conclusion:
The analysis demonstrated that MLP combined with TF-IDF is most effective for text classification in this dataset. While preprocessing typically mitigates overfitting, the experiment revealed minimal differences in performance between processed and raw data, suggesting dataset quality was robust.
Reflection: Future iterations will focus on, deeper dataset reviews to mitigate classification issues, advanced feature engineering techniques, and improved project planning and scope management.
- Text Classification
- NLP Applications
- Machine Learning Models
- Model Evaluation Metrics
Visualisations
 <
<